Business-specific, not generic
Scored against your product's standard, your domain rules, and your workflow — so you can trust a pass, not take a generic “looks reasonable” on faith.
Adversarial Evals
MCP ready*We generate the adversarial and edge cases that expose where your LLM or agent fails, then build an evaluator that catches them on every change. An eval tool that finds and measures failures, not a security firewall.
First evaluator free · No card · Your data stays private
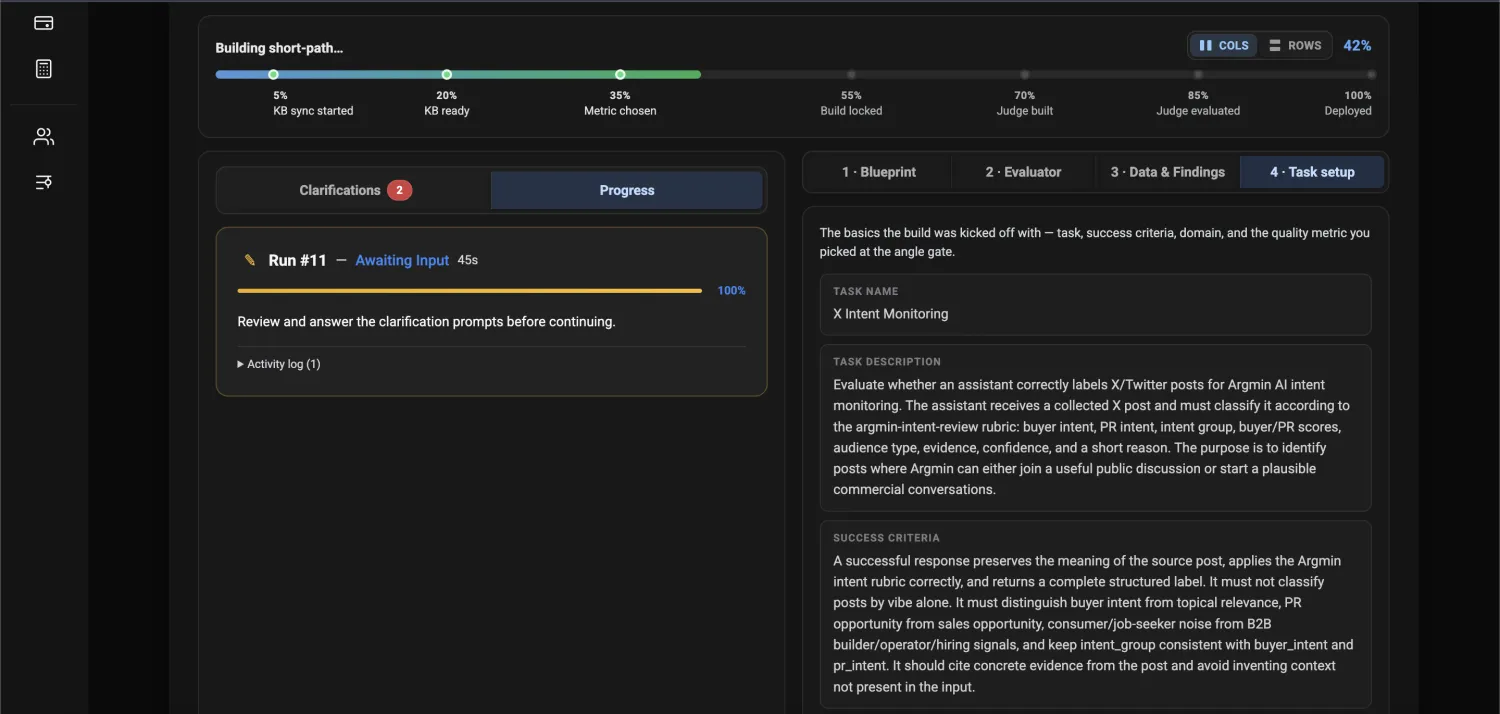
See how a prototype becomes a reliably-tested product.
Your AI handles the easy cases. You don't know which edge cases quietly break it.
Why generic judges fail
A generic judge can tell you an answer sounds reasonable.
It cannot know your task, policies, edge cases, or expert standard until it is calibrated.
Where trust comes from
Scored against your product's standard, your domain rules, and your workflow — so you can trust a pass, not take a generic “looks reasonable” on faith.
Your experts' corrections become the rubric and the labels — it reuses their judgment, it doesn't replace them — so the judge scores the way your team would.
It cold-starts the judge and a calibrated test set from your traces, plus synthetic and adversarial cases.
Criterion-level scores with a reason for every pass or fail, so you see what broke and why.
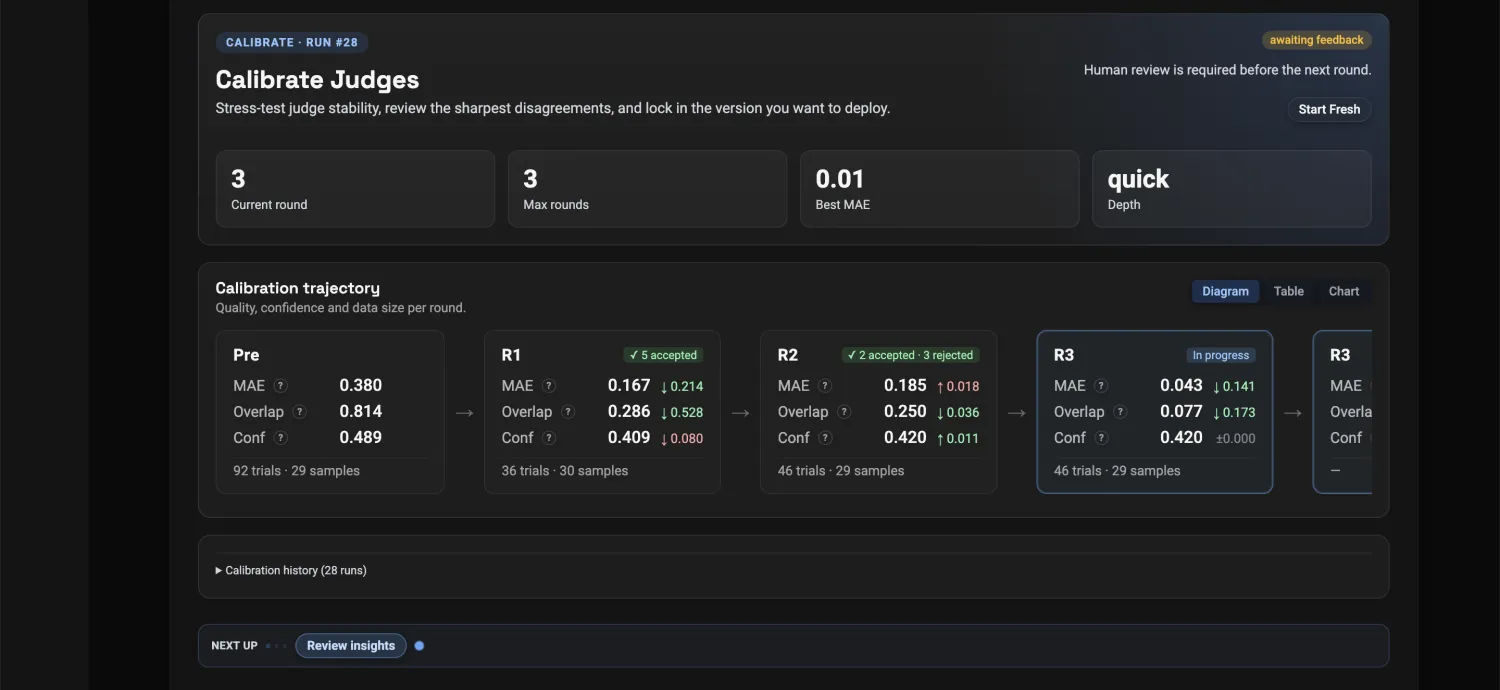
Versioned rubric and history; rerun it on every prompt, model, RAG, or agent change.
Outcome
Evaluator · calibrated
Rubrics, edge cases, and judges tuned to your domain and aligned with your experts. Ready to run on every model, prompt, or agent change so you see what improved and what broke.
Dataset · aligned
A lightweight, labeled set built during calibration. You confirm, override, or drop the labels, so it reflects your team's judgment, not the model's. Enough to start testing the AI agent you are building.
Process
A calibration flow for teams that do not have a clean golden dataset yet.
Start with the AI task, domain docs, selected traces, and a few hypotheses about what good looks like. No golden dataset is required upfront.
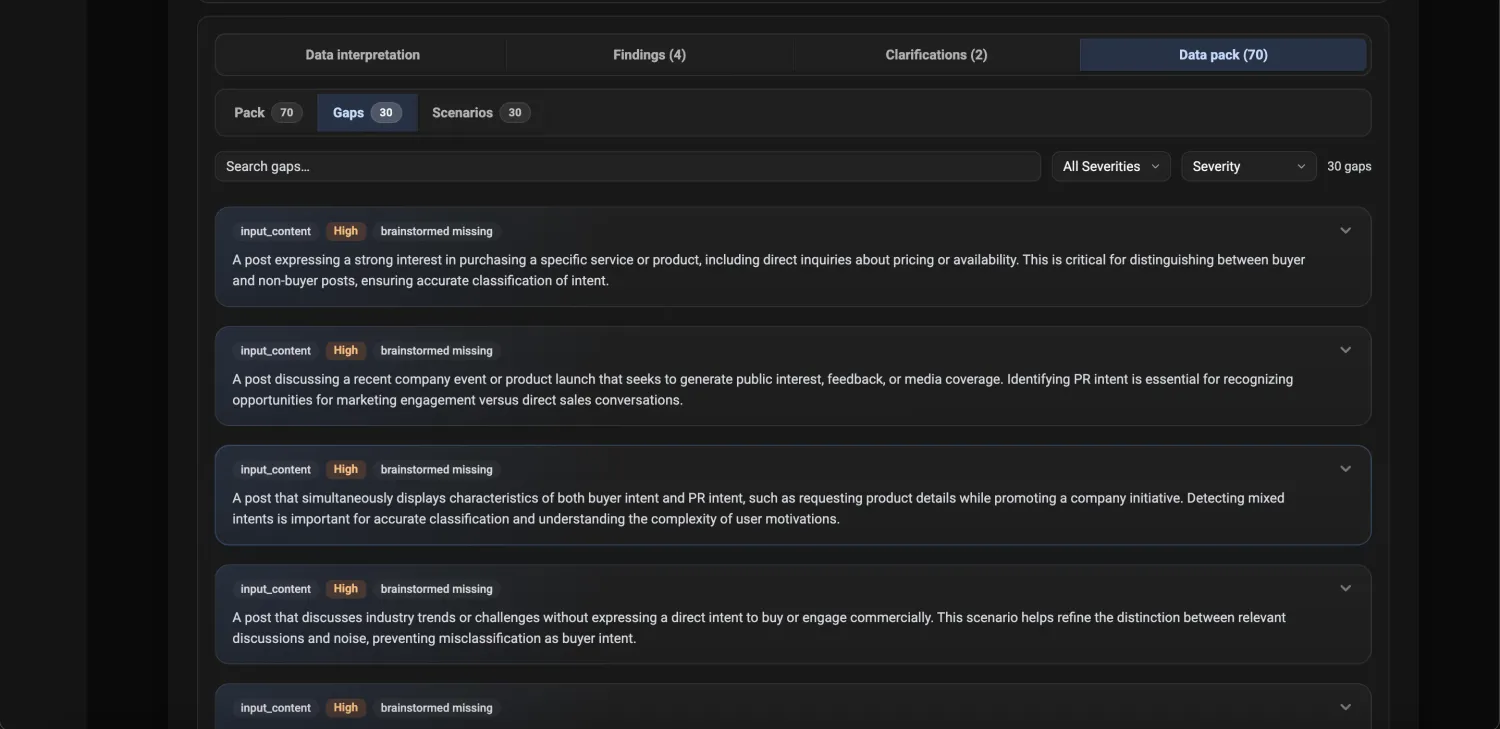
The platform finds normal, edge, and high-risk examples and surfaces where the evaluator disagrees with experts, so review time is spent on cases that actually move agreement.
Experts review and correct evaluator calls Argmin AI drafts first, never from a blank page.
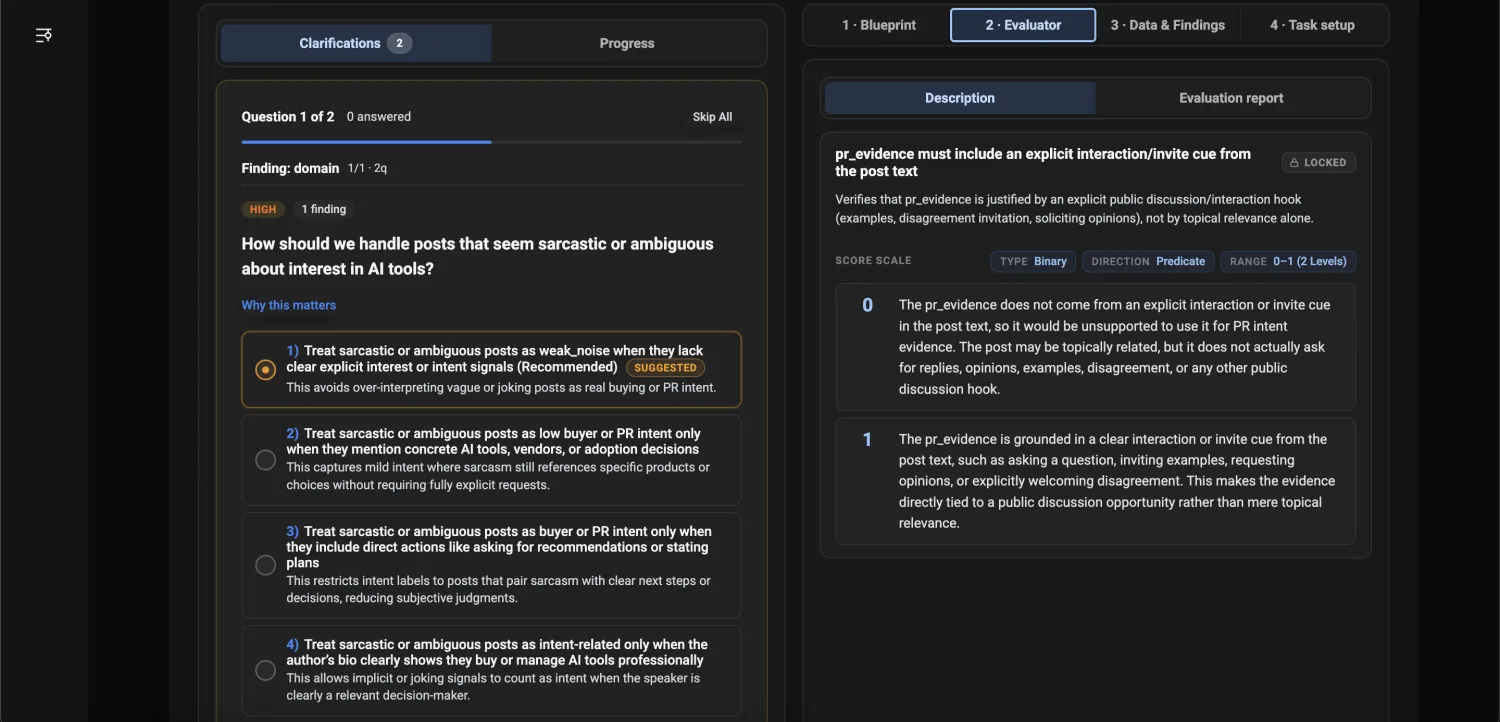
Every correction sharpens the evaluator and updates the calibrated eval set, quality rubric, score anchors, and calibration history.
Use the evaluator on prompt edits, model switches, RAG updates, routing changes, and agent releases.
Validation
0.0%
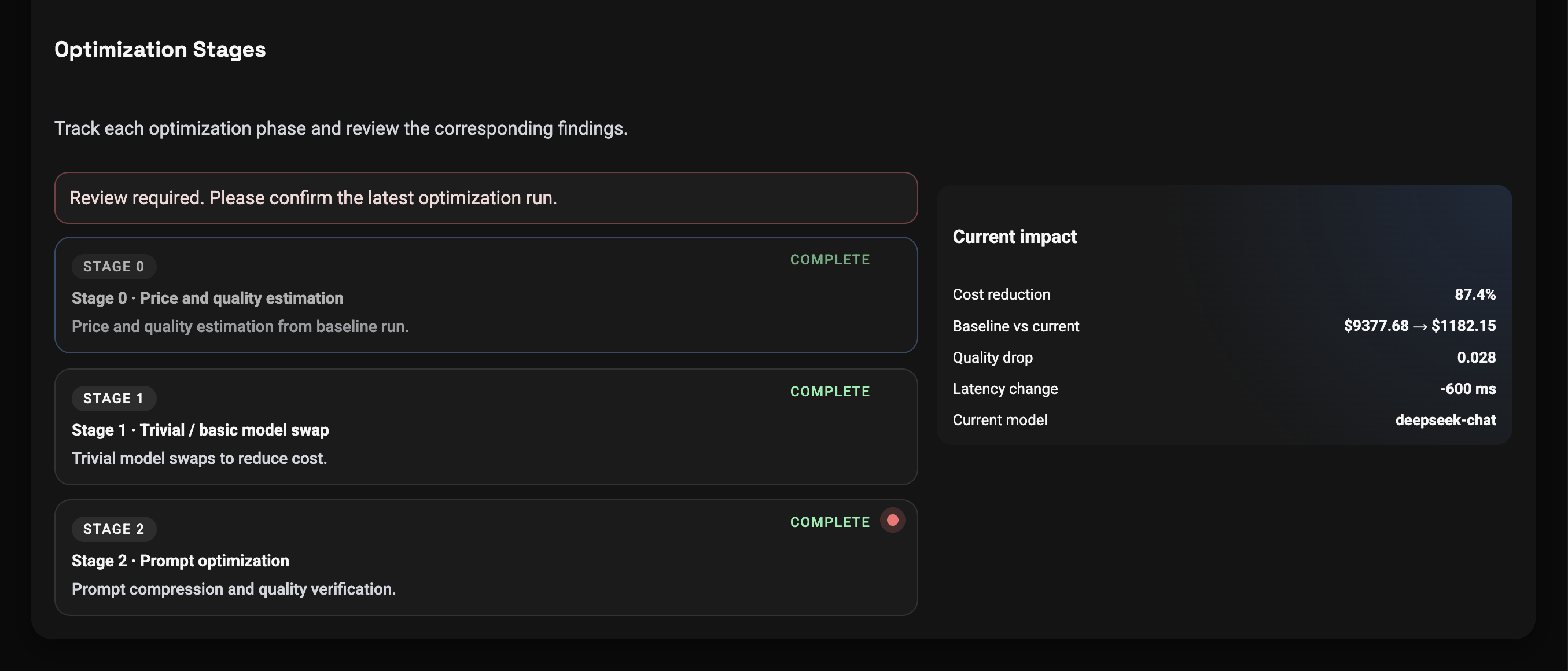
Safety maintained while optimizing cost
0%
Cost optimization
0
Edge cases
0
Evaluators
Main challenge: Move from manual spot checks to repeatable AI QA
Quality stops being a debate. Versions can be compared. Regressions are caught before production. Teams know why an answer passed or failed.
Enter your email and we'll send the case study PDF.
We process your email to provide access and start the whitepaper delivery flow. You can read our Privacy Policy.
Walkthrough
See how a prototype assistant gets a calibrated evaluator, test set, and regression workflow.
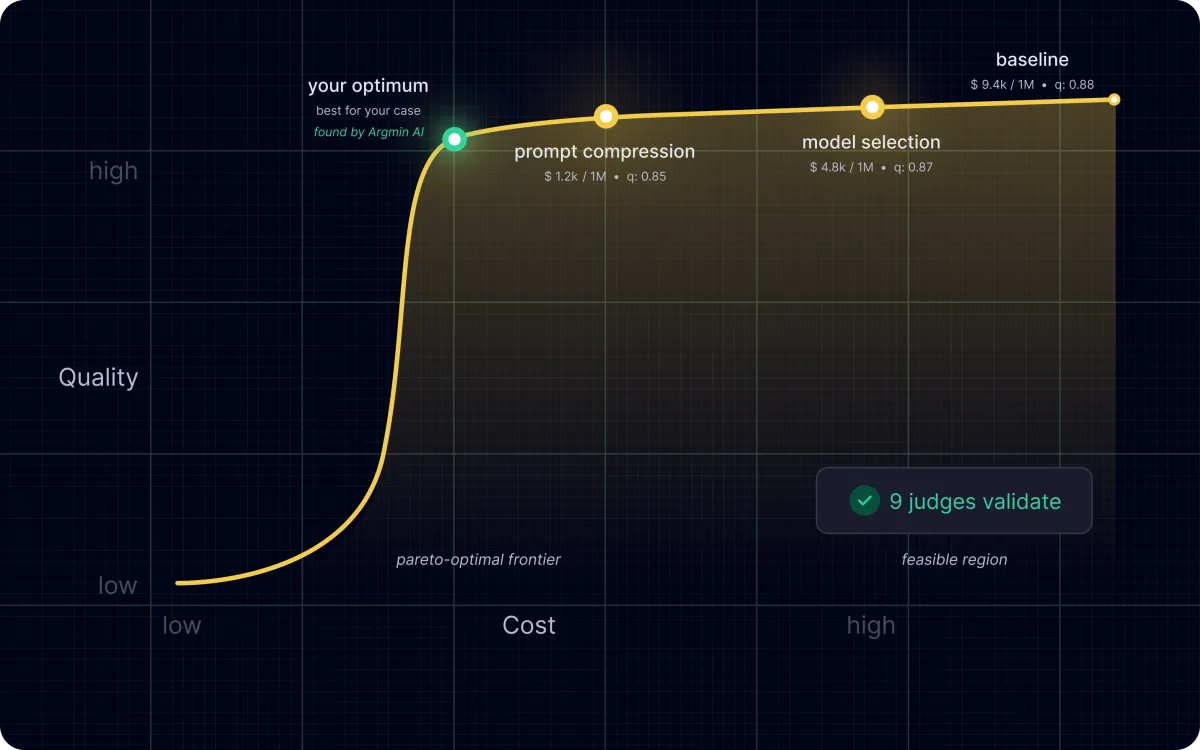
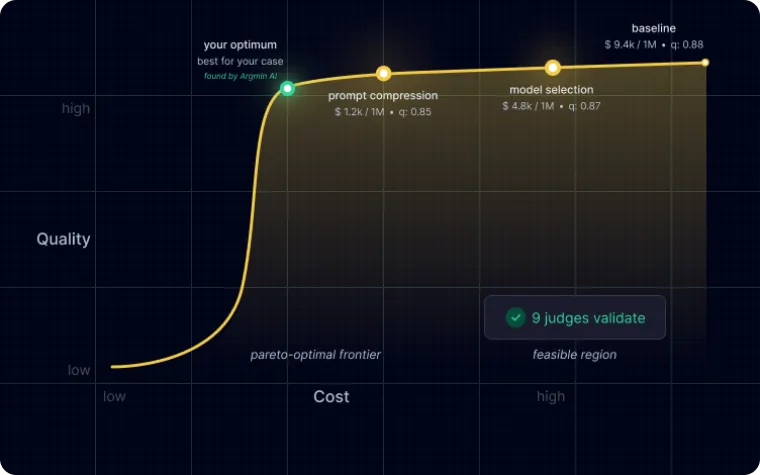
We generate the hard cases, then evaluate against them.

Move from “the new version feels better” to specific, measurable answer-quality dimensions.

Calibrated test sets built from real examples, expert cases, synthetic edge cases, and past failures.

Custom judges score every release and explain why an answer passed or failed, not just a single number.

Every correction is versioned and reused next time you change a prompt, model, RAG pipeline, or agent step.
Quality definition / Real-world coverage / Regression evidence
Your data stays privatePrivate by default
Used only to build and run your evaluator.
We don't train on itNever used to train
Never used to train shared models.
You decide what's sharedYou control sharing
NDA and tighter infra available on request.
1 free run to test1 free test run
No card required. See it work on your data first.